TL;DR
Origin Note
I have been working with microservices for some time. There is one question that keeps coming back when I work with them or discuss them with people. How small or big a microservice needs to be? The below blog post is my attempt to explain (& understand) the concepts around this & express my opinions/inferences along with it.
At the outset, I need to establish some context about microservices. A very short journey into history & a foray into the realm of definitions will help us understand the core topic better.
Before microservices there was…
Microservices have been around for some time now, but they are relatively nascent compared to these older fellows which I am going to describe now.
At the beginning of time there was Client Server architecture! Ok, that is not the truth, I have only gone back a few decades here. There were other architecture styles before, but they are not relevant to our conversation. Also, I am not explaining the entire computing history. The two relevant architecture styles are listed below:
- N-tier architecture (client/server?)
- Service Oriented architecture
Let us dig a little deeper.
N-tier Architecture
This architecture started off as the basic client server architecture which is two tiers. It was just a thick client which talked to a server typically for data storage. This obviously had some problems & hence things evolved. Cutting things short, we get to the final (or at least prevalent) incarnation of this architecture: the 3 tier architecture.
The tiers in a 3 tier architecture are:
- A thin client, like the browser
- A thick middle tier server component, which held all the business logic
- A data store, which held all the data.
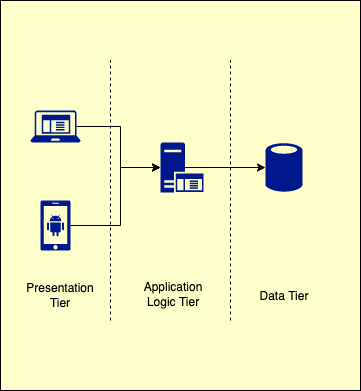
Fig 1: N(3) Tier Architecture
I am sure this is familiar to all of you as it is a valid architecture style even today. Monoliths were/are basically 3 tier applications in all their pomp & glory (and extra cheese!). Actually, many of the microservices today follow the same architecture.
The 3 tier architecture was embraced wholeheartedly by the software community. Advanced middle tier components called application servers got built with tonnes of features, to make it easy for developers to deploy 3 tier applications. This lead to creation of highly capable applications which can deliver a lot of useful functionality to multiple thin clients.
Lo & Behold! The Monolith was born!
Service Oriented Architecture
I think this architecture’s inception happened like this (purely a figment of my imagination) :
- Software people always want to reuse code & leverage functionality in other existing applications without having to change them much (so use them remotely).
- Software people always like to componentize things.
- These folks come across XML & figured out that this language can be used to represent any piece of data & can be read by any tech (Side note: there was a platform war going on at that time in tech history just like now there is cloud war going on).
- Then they put all these together & SOA was born.
I am just making this up and hence will be missing a lot of details (the individual aspects mentioned here are true but the story itself is fictional).
One key thing I did not specify yet are the Service Design principles which are very important (according to me). So let us focus on them:
- Standard contract & Service abstraction
- Service autonomy (implementation & location)
- Service discoverability
- Service statelessness
- Service composability
- Service reusability
If you look at these principles, they all make sense even today. Don’t they? I would even wager that they make even more sense today. Especially in the context of microservices.
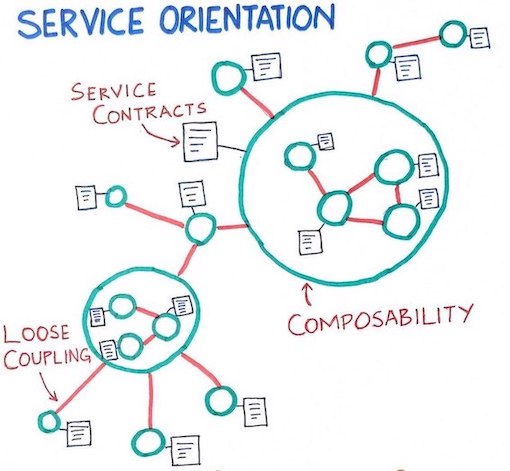
Fig 2: Service Oriented Architecture
While the SOA principles were (/are) very strong, the real world implementations got ugly soon. Given the enterprise focus of SOA, things changed for the worse. Enterprises already had a lot of software applications lying around & working in silos. Software Vendors took the SOA’s promise of reusability & interoperability & created all sorts of products (read ESB 😖) which were supposed to help these enterprises to leverage these siloed apps. This did not go as planned since such a transformation requires a lot of fundamental change in how these enterprises work, which mere tools can’t make happen. Enterprises made a lot of upfront investment on these vendor products expecting them to do some kind of magic. Of course, they did not get much out of it in the timeline they wanted it on. Not only that, these products became single point of failures (both from a dev & runtime perspective).
Apart from the above progression, there was one more issue. To solve a wide range of problems in these products & in general within SOA, many standards were evolved (WS*). While this effort was admirable, it did not sit well with developers since it meant a lot of complex artifacts added, which felt like boilerplate since they did not add visible value.
All said and done, I don’t think SOA is dead. It has just morphed to what is called microservices now (my opinion).
Why microservices (instead of monolith)
I am not going to explain the microservice architecture since in today’s world everyone has a pretty good idea about it. Instead, I am going to explore the reasons why microservices are preferred over monoliths. I get into this, because these attributes come into play when we eventually want to figure out the right size of a microservice. Remember when a microservice gets too big, it becomes a monolith. (When it gets too small then it becomes a nano/pico service).
There are some well known reasons for preferring microservices:
1. Independent Deployment
Microservices are fantastic because they allow for independent deployment of specific changes. When a feature requires localized changes on a particular module (or code path), a microservice (which represents that module) will allow us to deploy that part alone (by deploying the microservice) instead of deploying the entire functionality (app) which is required in case of a monolith. This plays out in many business scenarios.
This is a pretty crucial aspect of a microservice. If this is not realized then the point of having microservices is lost.
2. Freedom of tech choices
Given that microservices focus on a smaller cohesive footprint, they allow for more flexibility in tech choices. As they say, you can use the right tool for the job!
3. Easy replaceability
The ability to take a microservice out & replace it with a new one, in a relatively short amount of time, is cool. This is of course not possible with a monolith. This is another key aspect of a microservice. It allows us product developers to make mistakes & correct them.
Having said that, in the real world, we forget this & expect that everything works perfectly, the first time. Rewriting or replacing is always considered as an unacceptable thing. This defeats one of the great benefits of microservices - the ability to make a mistake & learn from it.
4. Shorter time to market
Microservices allow for a focused approach. Whenever the business wants to create a new feature, the focus of the corresponding team & its microservice(s) allows them to independently build out the feature & release it. This means that we are faster to market.
5. Independent scaling
In my experience, this is the favorite reason people think about & give others, when wanting to create microservices. Scaling is a problem everybody wants to have & solve. The microservice architecture’s capability of making this happen is the most important reason for everyone to flock to this architecture style.
Many times this solution leads people down the path of very small services (nano/pico services) which may not really solve the actual scalability problem. That said, no one can refute that microservice architecture when applied correctly can provide you ways to independently scale different parts of the bigger system, and that, is surely an advantage.
Now that the obvious ones are done, there are some advantages of microservices which are important but not appreciated as much:
1. Organized around Business Capabilities
The premise of a microservice is that it is organized around business capabilities. For example, you might create a microservice for payment management (‘Payments’) & another for order management (‘Orders’). Each of these are distinct business capabilities and have different concerns, interactions & business focus. This type of organization leads microservices to evolve independently based on what a particular business team (domain experts) wants to do in that specific area.
For example, if we want to use a different payment gateway because it provides better success rates, it is the ‘Payments’ microservice which will work & evolve this feature. The ‘Orders’ microservice does not bother about this.
Also, by doing this there is easier alignment of engineering teams with business goals, and it helps the team to build domain specific knowledge, which can help in making quicker & better decisions during development.
Some earlier mentioned benefits like shorter time to market, independent deployment etc. work because of this aspect of microservices.
2. Strong Interfaces
Once you go down the path of microservices, we would have split a large app into smaller services. The interactions between them need to happen remotely through an interface. This interface has to be clearly defined, is generally coarse grained, and all interactions happen only through it.
While we don’t want too many such interactions happening for fulfilling a single user action, when these calls do happen, they happen in a well-defined & clear manner. This reduces coupling between systems. Also, with proper microservices we reduce the creeping up of multiple concepts within a single service which removes cognitive overload.
In summary, two different microservices or sub-systems always talk to each other through strong well-defined interfaces. This leads to a lot of good things in the life of developers of both systems.
3. Decentralized governance
We already covered the fact that there is freedom of choice in terms of technologies used when we use microservices. That is part of governance, but that is not all of it. With microservices, individual microservice teams can even choose different processes & tools to run their development.
While, there needs to be a set of guidelines & some basic oversight to ensure that the fruit does not fall too far away from the tree, the need to govern everything through committee is reduced. This means that the dimensions of freedom for teams are much higher, leading to a more agile engineering organization.
What does “micro” mean?
Now that we have covered why microservices, let us move back towards the question of this write-up. What does “micro” mean in a microservice? What is the right size of a microservice?
The rest of the blog post is about answering that in detail. But to start off, I thought that I could briefly cover some points which people say about size of microservices. I am mentioning the extreme ones here because that has been my experience. More reasonable ideas on the right size of microservices will be presented down the line.
200 Lines of Code 😖
One of the metrics people use to talk about microservice size is lines of code. There are claims that microservices should be only 200 lines. There are others who say it can be 500 or 1000 lines. These absolute values don’t make sense to me, because lines of code can vary a lot depending on the language platform & the frameworks used in development. If I am building something using say, the RoR stack, a few lines of code would be enough to create a complete CRUD app. If I use direct Golang or C to build the same app the line of code required might be order of magnitude higher. So defining microservice size using lines of code count does not make sense to me.
A person per service 😕
Another famous one I have heard about the right size of a microservice is that it can be managed by a single person for the most part. This again does not make a lot of sense to me. Microservices are supposed to represent business functions. Typically, in any normal business function (unless you are very small startup), the processes followed are involved & are typically managed by multiple people. One developer catering to all these needs does not sound feasible to me.
An endpoint per service 😩
The third kind of logic I have heard is to split things up in such a way that a service only serves one endpoint. The argument is that one can scale this independently & hence it gives us a lot of advantage.
For me this setup does not make sense most of the time. If there is a business domain that only serves one API endpoint, I would be very surprised. There are potential niche domains for which this might happen. Even so, one API endpoint is cutting it too small. In my experience, I have never seen such a domain & I would love to hear from others if such domains exist.
There are other ideas of splitting the same domain into multiple services (since the domain needs more than one endpoint). This is a valid idea but when I probe deeper with these advocates, I find them expressing the idea of sharing a data store (database) across all these services. Once that happens, I find it difficult to stay with them. Sharing a data store breaks one of the fundamental principles of microservices - autonomy. That is not acceptable to me. So I walk away from the idea.
None of these ideas on the right size of microservices are good according to me (making it explicit in case my subtle hints were not clear enough), though I have heard them often. Now I will start describing some better ideas to figure out the right size of a microservice. But before I do that ( not again! ), I want to take an important digression. This digression is about Domain driven design, and to me, it is one of the vital ideas in the area of microservices.
Domain driven design
Domain driven design is a methodology or approach of developing software that focuses on a creating a software based model of the actual domain it is representing, thereby making the software model rich in concepts, processes & rules of the domain. It all started with a book created by Eric Evans.
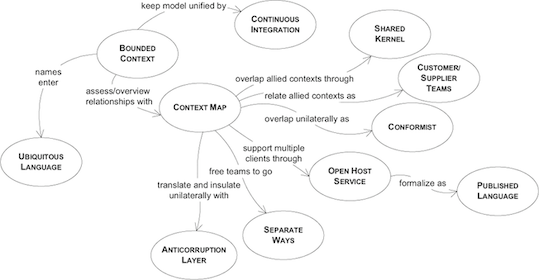
Fig 3: Domain Driven Design by Eric Evans: Model Integrity Patterns
This book focused on a bunch of concepts which I will describe very briefly in this write-up. I am touching this area of study because I think it is relevant to our topic - microservice & it’s right size. A detailed description is just not possible in this post. Given that more than one books have been written on the topic, there are multiple articles, courses etc. (and also communities), I will ask you to dive into one (or more) of them. May be down the line I will attempt to write something about it . Let us move to the crash course on the subject:
Bounded Contexts
One of the key ideas in domain driven design (DDD) is to organize large systems according to their business domains. As soon as I say this, I am sure you would realize that this is fantastic in the context of microservices. Microservices are also organized around business capabilities, so this seems like a good match to start with.
Within the context of a business area, we can define a domain model that makes sense within that context. Outside that context these domain concepts generally don’t make clear sense. Or at least they make different sense in different contexts. This boundary is defined as a “Bounded Context” & it is focused on a single domain. If you think a little, this idea is the foundation of microservices. A bounded context can be built using one or more microservices.
Ubiquitous Language
The next important concept of DDD is called the Ubiquitous Language. As the name suggests this means a language that is used across teams and disciplines - ubiquitous. It is a common language for developers & domain experts and is used to express business concepts & rules of the domain. The same language is also used to express concepts/rules in the software domain model. Let me reiterate: The idea is that software uses the terminology present in the business domain & makes it easy for business experts to understand the software as well.
This one does not contribute too much to the microservice architecture discussion, but I mentioned here because it is of fundamental importance in DDD.
Context maps
Any given business organization or super system is made up of multiple bounded contexts. There needs to be a way to describe how interactions between different bounded contexts happen. In the context of DDD, this interaction is expressed as Context maps. Context maps are very powerful to understand the business systems. It can also be very handy in figuring out our microservices. A context map could help us understand how our microservices work together, how they interact, their communication patterns, build and runtime dependencies etc.
Aggregates
There is one more important idea in DDD that I need to discuss here: “Aggregate”. This is one of the tactical design patterns presented in the DDD book. An aggregate represents a composite domain object which can contain one or more “entities” or “value objects” (these are other tactical patterns in DDD which I won’t cover) & ensures that invariants across these composed objects are kept intact. It also represents a consistency boundary.
An example could be an ‘Order’ & its ‘LineItems’. One of the rules/invariants could be the value of the order should be equal to sum of the values of its line items.
These are some key ideas of DDD & I have described them only as much as I require for explaining how they affect microservices & their size. There is a lot more to dig deeper in this area & I will provide references for the same, later in this write-up.
What is the right microservice size? - Considerations
Now that we are done with all the ceremony, we can get into the main discussion. Though I call it ceremony, I think the previous sections are relevant & will make this section much simpler to explain & understand. The following are the ideas, which we have to keep in mind when we think about the size of a microservice - how micro is micro?
Bounded Contexts
I covered bounded contexts in the earlier section. As I mentioned there, a microservice can contain a maximum of one bounded context. A bounded context represents a business domain & hence having a microservice representing more than one business domain defeats the main purpose of microservices - independence & autonomy. If two bounded contexts are present within a single microservice and one business team focused on a particular context wants changes on their aspects, then that will need to be synced with the needs of the other team & their bounded context. While keeping separate microservices does not guarantee that different business teams can work independently all the time, it takes it towards the best possible outcome.
Transaction Boundaries & Consistency
While the bounded context acts as a force on the upper bound of size for a microservice, the need to ensure that transactions work properly & data consistency is maintained in a given use case acts as a force on the lower bound.
There was a time when Java EE world thought they solved distributed transactions with 2 phase commit & everyone should be happy. But everyone was not happy. Scalability challenges & complexity of the architecture did not help the cause. Also, the solution of platform specific and everyone did not want to move to the Java EE stack for their own valid reasons.
As of today distributed transactions are not a solved problem at a tech level (there are patterns like Saga which help, but they add to the complexity). So if we want a user interaction to be properly managed as a transaction & consistency to be maintained for the data, then that interaction must not span microservices. It should begin & end within one microservice. If that does not happen then data consistency & good user experience cannot be guaranteed. Somehow in today’s world these things have become important! So this is a criterion to keep in mind to keep the service big enough.
The concept of an aggregate plays well in this aspect. Since an aggregate is a consistency boundary, a microservice that contains at least one entire aggregate and no partial aggregates, can meet this criterion. If an aggregate is split up into two microservices then it can cause havoc. So aggregate size acts as a lower bound to the size of a microservice.
Infrastructure Aspects
A new microservice typically needs a set of infrastructure components. There are the basic compute, memory & network needs and things generally don’t stop there. Most of these microservices will need other elements like databases & caches, and those need to be considered as part of infrastructure needs. And it does not stop here.
If you are going to develop & run a microservice, then a team needs to work on it. It needs to build, test & work with it. This means more infra needed for various environments like development, staging, testing etc. Keeping this in mind, creation of tiny microservices means adding to overhead in terms of infra needs. Our IT or Devops team may not be happy about it.
Having said all this, the current cloud based world (with spot instances & server-less infrastructure) makes this somewhat easier to manage or handle. But I still think it involves significant work & hence cannot be treated as a non-reason when it comes to creating microservices & their corresponding small size.
So before you think that I will split up the service to make it smaller keep the infra requirement in mind.
Iteration speed & Agility
One of the key purposes of creating microservices in an organization is to be able to improve its agility & iteration speed. An ideal microservice, which focuses on a specific business function, allows that function to quickly add new changes that can be shipped to customers to get quick feedback. This ability to ship a product/feature & get quick feedback is the hallmark of agility. This increased iteration speed is what allows organizations to keep ahead of their competition. The microservice architecture’s key benefit is to allow this to happen.
In terms of ‘right-sizing’ the microservice, this is another guiding principle. If the microservice size still allows our team to deliver in an agile manner then we are safe with its size. If it is slowing things down then it is potentially time to look at making changes to the size of the service (either split them or combine them). This consideration is slightly indirect but if we track our agile processes properly then this can be an eye-opener to determine microservice size.
Couple of opposing forces to note in this context:
- Typically, when services grow big, testing all the scenarios takes more time. So testing time increases with the size and hence it pushes services down to make them smaller.
- If a feature change needs developers to work with multiple services (within the same team) to release it, then overall development time increases. Developers have to work with all the services individually, test against their contracts (with & without mocks/stubs), deploy in different environments in a co-ordinated manner and also ensure distributed communication scenarios are handled. So if we want development time to be reduced within a context of business team it might be better to have a bigger service that caters to that business function fully.
Team Size (Two Pizzas team)
This criterion speaks a lot to engineering managers. Every manager wants to have a clear idea on the right (or good) team size for managing a microservice. The accepted intelligence out there is that a microservice team has as many members as can be fed by “two pizzas”. This means a size of around 6 - 10 members (few indicate that it can be up to 12 members). The original quote of “Pizza teams” came from Jeff Bezos.
From an agile team perspective, who constitutes a team? Is it the set of developers in the team? What about testers? What about engineering managers & product owners? In the literature out there, this aspect is not clear. So I am going to wing this part, based on my experience & intuition.
For me, an agile team which takes care of a business focus area or a domain should be the set of people who interact & communicate about it on a daily basis. Developers, testers & product owner(s), all form part of that team. Developers are focused in creating the feature, the testers are focused on ensuring quality of the feature & the product owner is the one responsible for envisioning the feature (I say ‘responsible’ to differentiate the fact that she does not have to be the only person doing the thinking, but she takes charge of the process). These members focus on the service/business area day in & day out. Another important criteria of an agile team is that they are self-managed.
If these two criteria are met, then those are the team members that manage the bounded context & they can be as big as 6 - 10 members. Let me summarize the types of people in the team so far (they are just in alphabetical order):
- Developers
- Product Owner(s)
- Testers
You might ask: What about the engineering manager? If the engineering manager is solely focused on the team & contributing to the teams work on a regular basis then they could also be considered in the 10 member gang. But if they have a broader focus & are indirectly involved with the team and engage at higher level, then I would consider them to be sitting outside the 10 member team. Similar approach can be applied to members from Devops, Security etc.
Back to the microservice size question. This agile team is focused on a bounded context/domain & hence need to manage one or more services within itself. It is ok for the team to manage just one service which takes care of all of business functions. Or the team might decide that it needs to manage it using 2 - 4 services. Either way, things work.
What does NOT work is this: For managing this domain specific service, if we start needing a team bigger than 10 people, then it may be time to split things up. This splitting up is not just about the service. If I need a team bigger than 10 people to manage a business subdomain then it means that the domain is more nuanced and/or broad. So the business needs to look at how to split the business function up to provide better focus on each of these parts. This part is purely my own opinion & hence subject to disagreement. I am ok with that.
The one thing we should not forget from this section is that team size acts as an upper limit determinant of microservice size and pushes it down.
Modularization
The concept of modularization is well known to a lot of us. We want modularization because it helps us to understand things easily & reuse things. Also, modules operate with each other through contracts, and contracts are always a good thing. Creating small modules to make a big system is not a new idea. It has been around for long.
Microservices take this to the next level where they are reusable deployed modules which can be used by others through an API contract. When a developer is working within a module, she doesn’t have to keep in mind a lot of other (external) concepts but can focus on only the ones that make sense in the given context.
When people use normal modules (that are not microservices) in an application, they tend to be less disciplined in their usage of other module code. They just import it anywhere they want & start using it as they like. This increases the coupling between modules. Microservices stop this kind of undisciplined usage since calling a microservice is a network call (there are associated costs) & it is generally done through a very strict contract (interactions typically happen using a specific pattern - client). This means that developers will adhere to module boundaries, and will be deliberate about module usage.
From a size perspective, small modules are always good. So as per modularization, small microservices are also good. That said modules need to be cohesive things which expose a single responsibility (or a single set of them). That applies to microservices too & if you can find the smallest cohesive set of functionality then we can make it into a microservice. In summary, modularization tend to make services smaller and push on upper bound to make things smaller.
The story does not stop here. Let us continue to the next one.
Refactorability
Refactorability as a term feels odd from an English perspective, but makes some sense from a perspective of developer. The way I understand it is that, it refers to the ability of a codebase to lend itself to easy refactoring. This ability depends on a lot of things. Generally good IDEs & editors provide this ability & they generally work better in the case of statically typed languages.
As a developer, refactoring code within a project, to create some clean & readable code has been one of the best joys I have experienced in my career. It rivals (even beats it sometimes) the feeling of building something completely from scratch.
Now back to the process of refactoring. Irrespective of the development platform, most of the IDEs allow you to refactor code within a project. They generally don’t allow you to refactor code across multiple projects. This is even more true in case these multiple projects refer to different microservices which are integrating over a structured contract made up of say JSON and are potentially implemented in different platforms.
While from a modularity standpoint, creating smaller & focused microservices is a good thing, when you do that, you tend to lose out the ability to easily refactor code. This again increases development time and hence something to consider.
So don’t make microservices so small that refactoring is very difficult. This generally won’t be problem if the concerns of microservices are quite separate (then they won’t have much commonality to refactor). To sum up, modularization is great, but it needs to be balanced with refactorability.
Scaling
One of the key reasons for creating microservices is the ability to independently scale small services as per their needs. Please take special note of the word independently in that sentence. When we say we can ‘independently’ scale, it should not just be a theoretical possibility. Creating small microservices that can scale separately since they deal with independent business use cases, is a good idea. But if that is not the case then there is a problem.
Let us take a counter example:
Let us say that a single business use case (which might include multiple user interactions) is spanning three services. Also, let us say that these services primarily serve this business use case only. So when you want to scale to serve more users of the business case concurrently, you will have to scale all the three services involved in a corresponding & related manner. This is really NOT independence of scaling. What this is, is a case where you don’t have any true independent scaling, but you have incurred all the cost of having a distributed system.
We need to keep this in mind before we decide to split things up to small services. So, while the idea of independent scaling will push the size of the service to be smaller, please keep in mind that unless things are truly independent, the point is lost.
I will even take an audacious step to say that we should not use scaling as a criterion for determining microservice size. I think the other concerns will anyway guide you in the direction of achieving maximum possible scale. Again this could be controversial to some, and I am open for discussion.
Replaceability
We talked about this criterion as a key advantage of microservices. Microservices allow engineering teams to build a first cut or pilot version of some functionality, and then throw it away, and replace it with something better. This promise makes a lot of sense for startups & even for established companies who are trying to innovate & stay ahead.
For doing this, the size of the microservice better be small so that we developers feel that it is ok to throw it out & build something in its place. If we have a microservice which is large & holds sizeable functionality then it becomes more difficult for developers to dismantle it. We won’t feel comfortable to quickly replace it. It will take a lot more effort & when that happens, teams tend to forgo the change. It becomes a case of not wanting to deal with the regression that the replacement might cause. So if we want replaceability, then the size of the microservice needs to be small. So this criterion pushes down from the upper limit.
Distributed Communication
We just learned that small microservices are great for replaceability. But small does not mean good all the time. When we have small services, we invariably need to communicate between them to get work done. Distributed communication is a very hard thing to do.
All of us have experienced working with distributed systems in one way or the other, and we all are aware of the fallacies of distributed computing. There are dozens of patterns that we can use to bring reliability in distributed communication (entire books have been written on them) but as the first law states to never distribute objects if we can get away with it.
So distributed communication comes with its own bag of issues (reliability & latency related). If we can keep this communication to a minimum then our systems will be better off. So this drives the size of microservice to be bigger - pushes up from the lower limit.
Size of a microservice - Summary
We looked at a set of considerations above which act as forces governing the right size of a microservice. Whether you are trying to design/architect a new microservice or evolve one from a monolith, these considerations should be kept in mind. Obviously this is not very easy. There is no simple formula to arrive at an optimum size of a microservice. (I know it feels like a letdown after reading this for such a long time. I am sorry! 🥺)
That said, giving a set of descriptions on these ideas is not an effective way to keep track of this information. In this section I will try to depict the above considerations into a more usable form in terms of quick reference. The idea is that once you understand the above considerations, this section could act as an easy reference for you to do the actual work of architecture.
The key considerations can be treated like forces. These forces act on the upper & lower limit of the size of microservice:
- Forces which push the service to be bigger, push at the lower limit not allowing it to get smaller.
- Forces which push the service to be smaller, push at the upper limit to not allow them to get bigger.
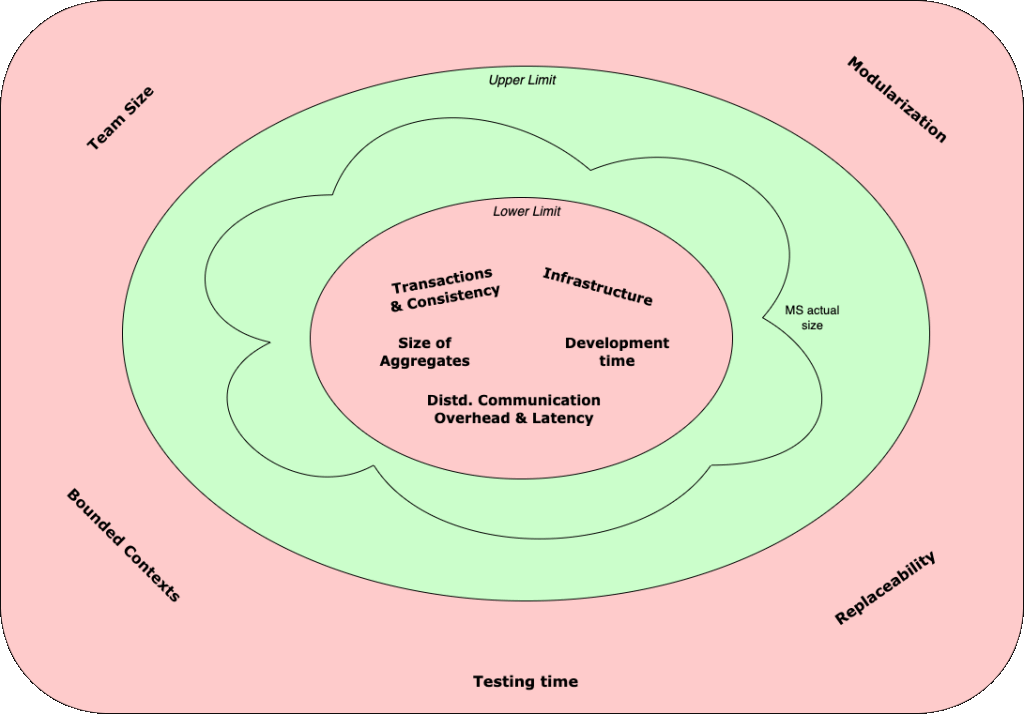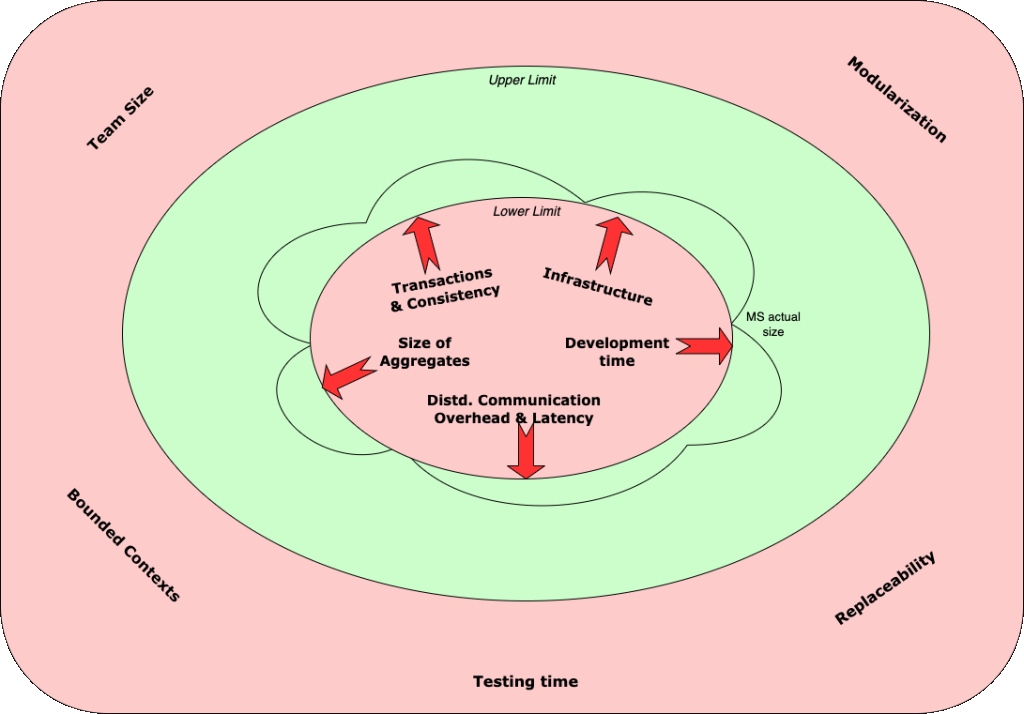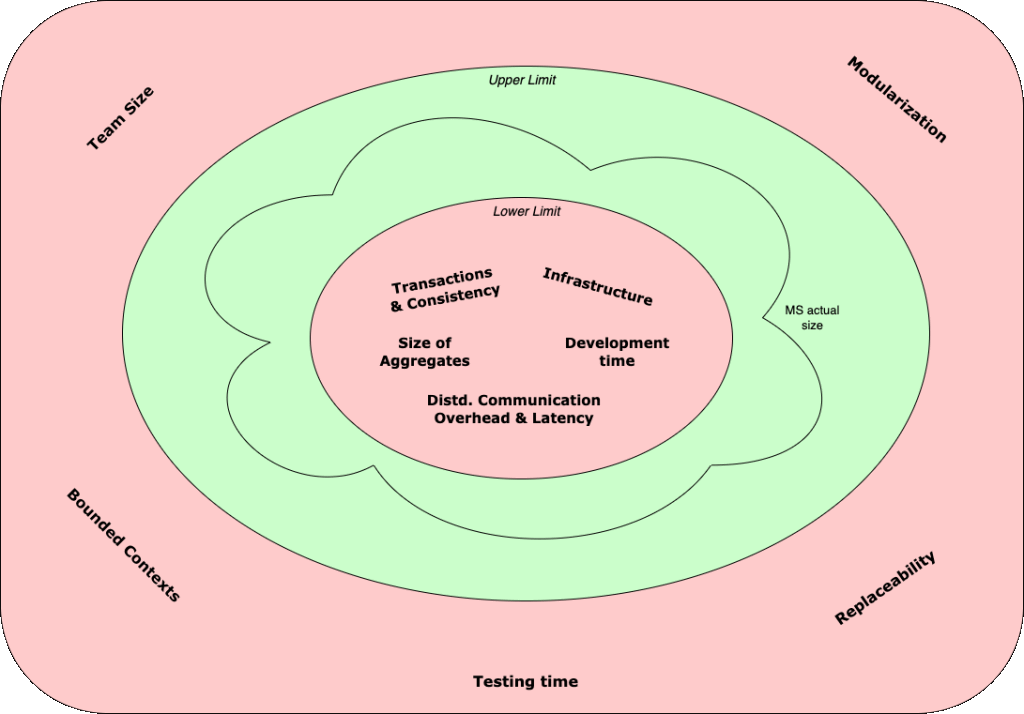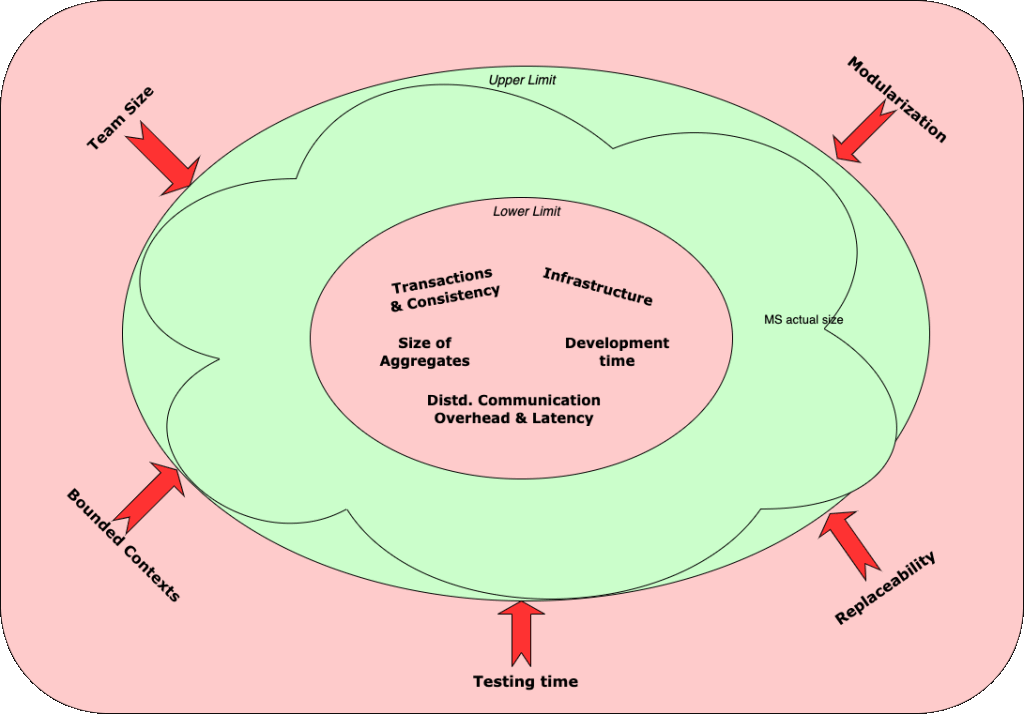
Fig 4: Key factors shown as forces affecting size of a microservice
I am also tabulating these factors along with the limit they influence for easy reference.
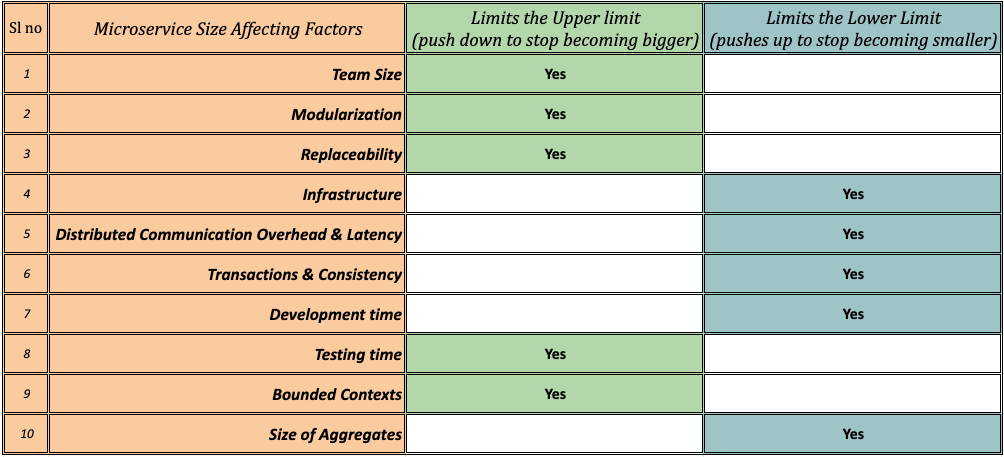
Fig 5: Key factors affecting size of a microservice tabulated
Hopefully these aids will help you remember/refer to the key ideas which these thousands of words are trying to convey.
Closing remarks
We have come to end of this long write-up. At the end I want to leave you with some informal ideas. When deciding to build (or building) or carving out a microservice:
- Focus on Business capabilities & Service boundaries
- Don’t look at Lines of Code (LoC)
- Get a clear understanding of the user interactions involved in your service and related services.
- Focus on enabling agility within & around the engineering team.
- Use techniques like Bounded contexts, Aggregate design, Event storming etc.
- Err on the side of bigger - It is relatively easier to split it up later rather than the other way around.
- Be cognizant of nano/pico services. They are only useful if they are very simple utilities
- It is not an “in vogue” thing, and you don’t have to join it if you don’t want to!
That’s it. We have come to the end. I have listed down all my references, so that you can go read & explore more. Please share your thoughts, comments, insights with me so that I can also learn from your experiences. Ciao!
For more on practical microservices challenges, I’ve also written about caching strategies in microservices and used a fictional bar conversation to explore timeouts and cascading failures — both connect directly to the distributed communication concerns raised above.
References & Explorations
- Microservices article in Martin Fowler blog
- Book: “Microservices: Flexible Software Architecture” by Eberhard Wolff
- Article: “What’s the right size for a Microservice?” by Kyle Brown
- Article: “How big is a microservice?” - by Ben Morris
- Book: “Domain-Driven Design: Tackling Complexity in the Heart of Software” by Eric Evans
- Book: “Domain-Driven Design Distilled” by Vaughn Vernon
- Article: Event Storming