 Starting Point
Starting Point Nginx is one of the projects which I always felt a pull towards, owing to it architecture. It is "event driven"!. For some time, I have heard this but I always wanted to get more deeper into it. So I did some digging on how nginx works. I read many articles (will be referred below) and pieced it together to the best of my understanding. Here is my attempt to explain how I think it works!
Of course take this with generous helping of salt:
- I don't have much knowledge on linux internals and syscalls - so whatever I describe is surely going to have faults/mistakes. I look forward to get help from others to correct it.
- Another reason is that I did not go through the nginx source code. I don't have expertise in C and I am too scared to peep into nginx codebase for the fear of getting completely lost.
Now that is out of the way let us get started.
Background - Process Roles
Okay. Before we get started let us get some background on the nginx processes.
Nginx follows an event driven architecture and has different types of processes doing specific kinds of tasks. Let me first describe these process type and their roles. Once that is out of the way, I can get to more details on how the nginx startup and processes requests.
The four different kinds of processes are:
Master
The master process is what starts up and manages the lifecycle of all nginx processes.
Worker
This is the work horse of nginx. This process is the one which does all processing for client requests. Reverse proxying, load balancing, compression, ssl termination etc. are all done by this process. Generally there could more than one of these processes running at any given time.
Cache related processes
- Cache loader process This process checks the on-disk cache items and populates nginx in-memory db with cache metadata. It prepares nginx to work with files already cached and exits after updating in-memory db
- Cache manager process This process manages cache expiration and invalidation. It stays in memory.
That should be enough background. Let us deep dive into how nginx starts and processes requests. For this discussion the processes under focus are only the master and the worker processes.
See it yourselves
If you want to see these processes in action. Do the following (assuming you have done the installation): Open a terminal/shell and execute
watch -n 1 "sudo ps -eFww --forest | grep 'nginx\|PID'"
In another terminal execute
sudo nginx
You can drop the sudo if your nginx does not have reserved ports configured for listening.
Once you start nginx, you should see the processes in the first terminal window. Keep watching it for sometime (you might notice something).
Nginx startup
You start nginx by calling nginx. Let us look at what each of the main processes do at this point
The Master (A true leader/delegator)
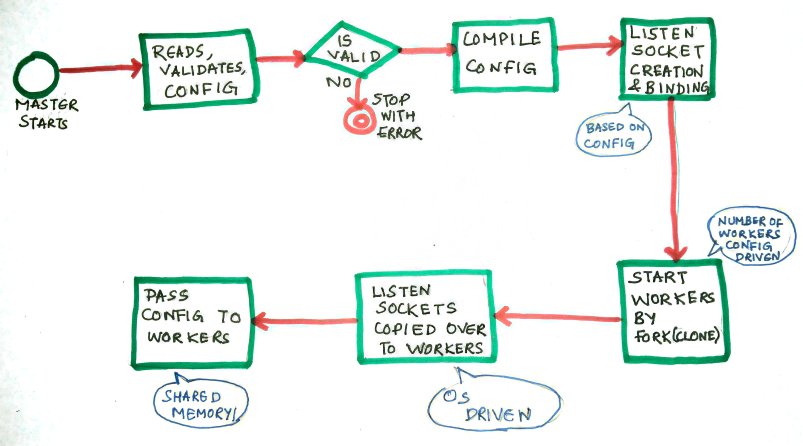
The first process to start is the master process. It first reads through, validates and compiles the configuration. Once the configuration is validated and compiled, it looks at the configuration to figure out what all listen sockets have to be created for serving client requests.
The server connection establishment process starts at this point for the required listen sockets. As a server (role played in client server communication), the master first tries to create sockets and bind to the ports defined in the configuration. One thing to note is that if the defined ports belong to the reserved set, the nginx needs to be started as a privileged user (root/sudo). Once the socket is created and binded it will also set the socket to listen mode with a default backlog of 511 (read more about listen backlog from references).
The next step the nginx master does is to start the worker processes. This is typically done by forking (clone) them out as a child process (this is my assumption/understanding). This also means that listen sockets descriptors are copied over to the child processes and are hence accessible to the workers. The compiled configuration is also passed onto the them. The number of worker processes to be created is based on configuration. The typical default is auto which leads to the creation as many workers as there are cores in the machine (or VM).
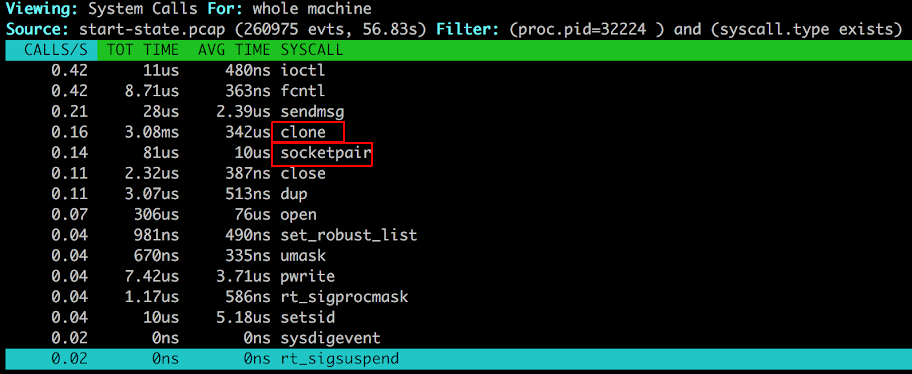
The Worker (I am awake!)
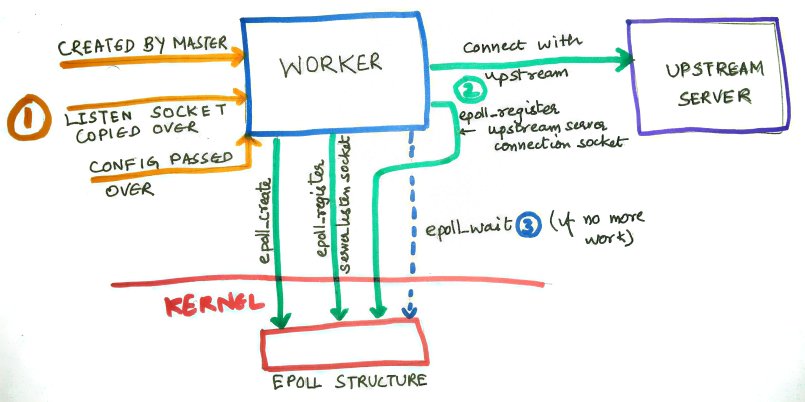
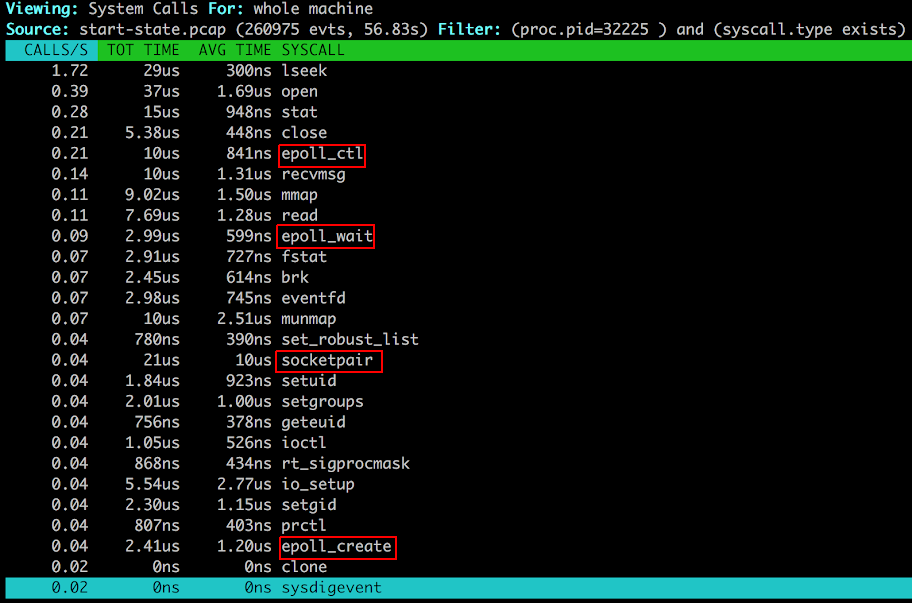
Each worker creates a epoll data structure with the kernel (using epoll_create). It then registers the listen socket descriptor to it using epoll_ctl and asks the kernel to let it know if there are any events (read or write) on the listen socket(s). All the different workers have access to the listen socket and they concurrently share the requests coming to them. Eventually if the worker has no other work to do it would block using epoll_wait.
Each of the workers also create non-blocking connection sockets to upstream servers so that they can act as proxies to them. This also is event based and hence based on epoll.
Nginx processing requests
Now that nginx has started, it is time to process requests.
The Master (time to sleep)
At this point the master pretty much does nothing. It does not have any work to do during the time of processing requests.

The Worker (A superstar)
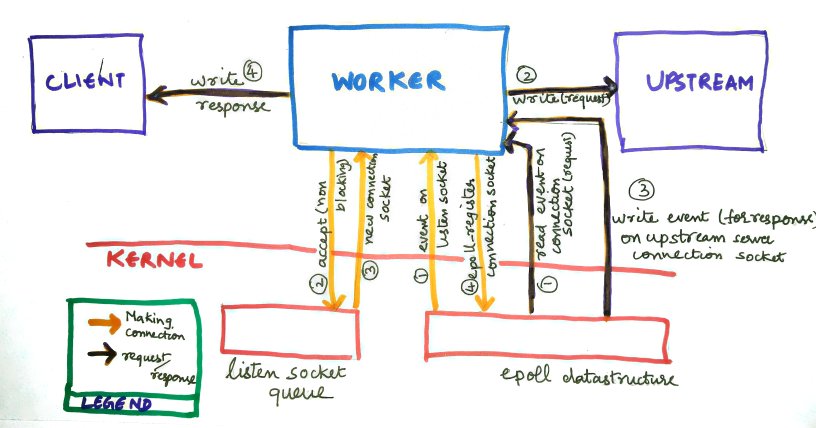
When a new client connection request comes to the listen socket, the linux kernel will pick the latest added worker process among epoll those waiting in the listen queue and send an event.
This worker process would then do a non-blocking accept call which will create a connection socket between the client and server. This connection is now going to be served by this worker process. The worker does the same thing with the connection socket as it did with the listen socket. It registers interest on IO events happening on that socket through epoll_ctl and waits for events with epoll_wait if it has no other work to do.
Over a period of time you will find that a worker process ends up serving many connections at the same time. Each of these connections are registered within their (worker's) own epoll data structure. At the end of epoll_wait, the worker might get multiple sockets which are ready for processing. It then processes each of those requests. Processing of incoming request might include acting as a reverse proxy (write out the request to upstream server), do ssl termination etc. On the other hand processing of the response could be compressing the response read from the up stream server (again this is event based using epoll), and write out the response to the client again in non-blocking fashion. The worker is the one which exhibits all the wonderful features of nginx.
The worker processes do not use epoll based asynchronous IO for files. For files it does blocking IO in most cases. If AIO is well supported in a platform it might use the same. But generally file IO slowness can lead to blocking behavior in the worker (and hence nginx).
See the worker in action
Do you want to see the workers in action? Go ahead and watch the connections using the following command:
watch -n 1 "sudo netstat -npt | grep :80"
With that watch running go ahead and hit your nginx server using ab or something similar. You should see the connections swelling up. Of course I have assumed here that the port nginx is listening to is 80. Change it according to your setup.
What is all this fuss about!
Nginx does all this to provide high scalability.
The worker's power
A nginx worker can process 1000s of connections at the same time because of its non-blocking event based nature. Because of this nature, the cost per new connection in nginx is a matter of space for a new file descriptor and data structures needed to manage that socket's information. This is unlike other servers which have a process driven architecture (apache) which needs to allocate much more memory due to creation of process (stack and heap).
Also the creation of limited number of worker processes in nginx means they can remain pinned to the cpu cores and avoid excessive context switching.
But then it is not all roses
Earlier I mentioned that the linux kernel keeps picking up the latest added process to distribute connection requests coming into the listen sockets, it happens that one of the workers get the lion share of the work load and hence the multi-core usage becomes skewed - more on one process. You will find more information in one of the articles in the references section.
The master strikes back.
From the above it looks like the worker is the only star and master is just sleeping. But the sleeping giant plays an important role in keeping nginx running when reloading configuration changes or even doing a nginx binary upgrade. You can find out more about this in the articles in references.
Conclusion
As I said earlier, what I have tried here is to give an overview of how nginx goes about serving its clients at a slightly more detail level. I have used the following references as a way to understand most of this. And of course I might have got some of the connecting pieces wrong. If anybody can find these gaps please chime in. Thanks for being here!
References
- Inside NGINX: How We Designed for Performance & Scale - Gives a good idea on Nginx architecture. Also covers how the master is able to handle config changes or binary upgrades without downtime.
- Nginx Tutorial #1: Basic Concepts - Just basic idea on running nginx and some basic configuration
- nginx - A deep dive on nginx architecture by one of nginx architects
- Tuning NGINX for Performance - Gives you ideas for improving nginx performance
- Know your TCP system call sequences - A general article covering system calls related to TCP connection creation and management. Covers listen backlog too.
- Why does one NGINX worker take all the load? - This article talks about how it happens that one nginx worker ends up getting a lot more load than others and what you can potentially do about it.
- The method to epoll’s madness - A good article on how epoll works.
- Does Nginx block on file IO? - A discussion thread on how nginx file reading works.
- Sysdig - This is what I used for determining those sys calls that were happening on each of the processes under different conditions.
Comments
comments powered by Disqus